Advanced Usage
Architecture
A Pypeln pipeline has the following structure:
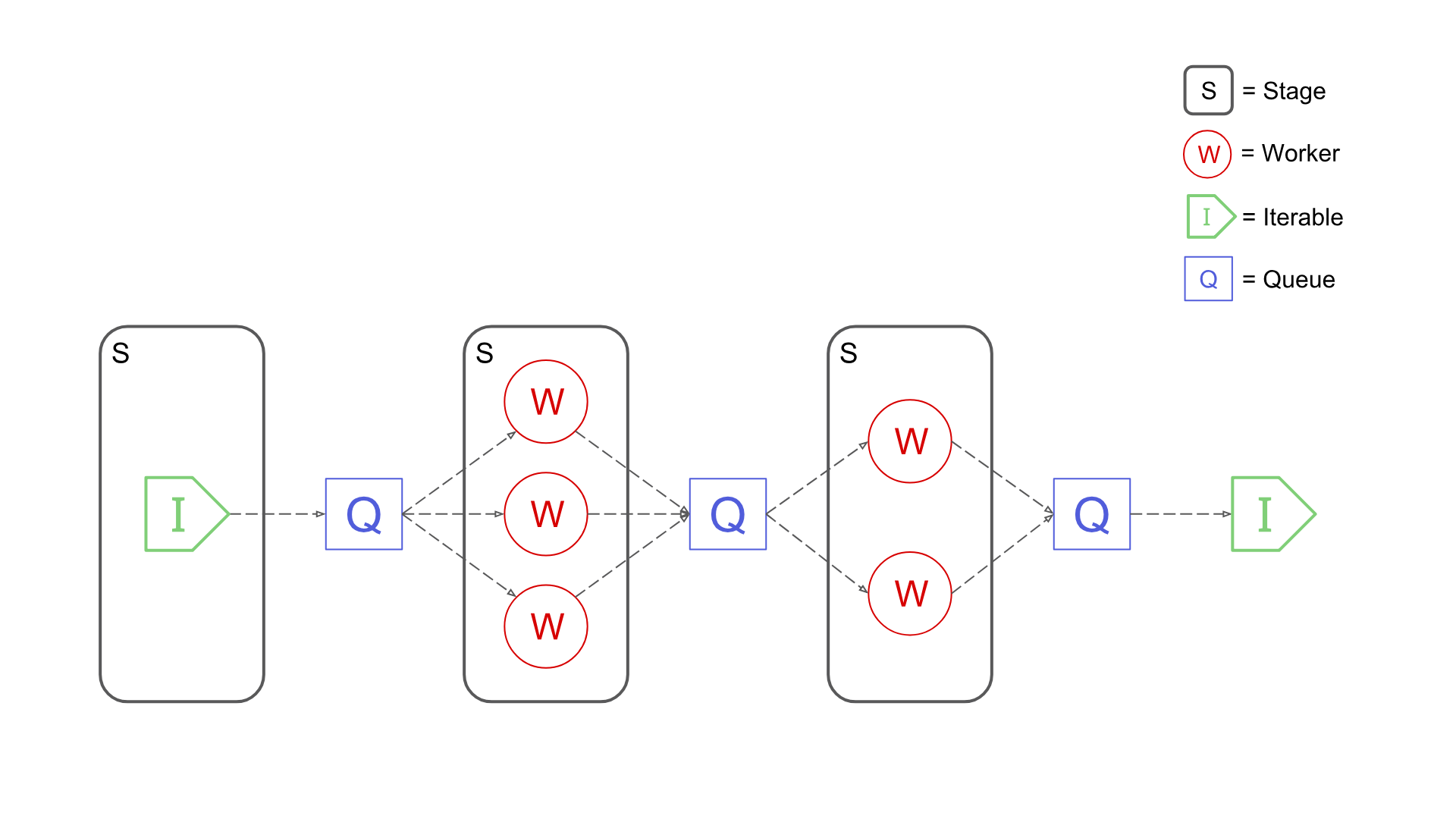
- Its composed of several concurrent stages
- At each stage it contains one or more worker entities that perform a task.
- Related stages are connected by a queue, workers from one stage put items into it, and workers from the other stage get items from it.
- Source stages consume iterables.
- Sink stages can be converted into iterables which consume them.
Stage Types
Pypeln has 3 types of stages, each stage has an associated worker and queue types:
| Stage Type | Worker | Queue |
|---|---|---|
pl.process.Stage |
multiprocessing.Process |
multiprocessing.Queue |
pl.thread.Stage |
threading.Thread |
queue.Queue |
pl.task.Stage |
asyncio.Task |
asyncio.Queue |
Depending on the type of stage you use the following characteristics will vary: memory management, concurrency, parallelism, inter-stage communication overhead, worker initialization overhead:
| Stage Type | Memory | Concurrency | Parallelism | Communication Overhead | Initialization Overhead |
|---|---|---|---|---|---|
process |
independent | cpu + IO | cpu + IO | high | high |
thread |
shared | only for IO | only for IO | none | mid |
task |
shared | optimized IO | optimized IO | none | low |
Stages
Stages are lazy iterable objects that only contain meta information about the computation, to actually execute a pipeline you can iterate over it using a for loop, calling list, pl.<module>.run, etc. For example:
import pypeln as pl
import time
from random import random
def slow_add1(x):
time.sleep(random()) # <= some slow computation
return x + 1
data = range(10) # [0, 1, 2, ..., 9]
stage = pl.process.map(slow_add1, data, workers=3, maxsize=4)
for x in stage:
print(x) # e.g. 2, 1, 5, 6, 3, 4, 7, 8, 9, 10
This example uses pl.process but it works the same for all the other modules. Since pypeln implements the Iterable interface it becomes very intuitive to use and compatible with most other python code.
Workers
Each Stage defines a number of workers which can usually be controlled by the workers parameter on pypeln's various functions. In general try not to create more workers than the number of cores you have on your machine or else they will end up fighting for resources, but this varies with the type of worker. The following table shows the relative cost in memory + cpu usage of creating each worker:
| Worker | Memory + CPU Cost |
|---|---|
Process |
high |
Thread |
mid |
Task |
low |
General guidelines:
- Only use
processeswhen you need to perform heavy CPU operations in pararallel such as image processing, data transformations, etc. When forking aProcessall the memory is copied to the new process, intialization is slow, communications between processes is costly since python objects have to be serialized, but you effectly escape the GIL so you gain true parallelism. Threadsare very good for doing syncronous IO tasks such as interacting with the OS and libraries that yet don't expose aasyncAPI.Tasksare highly optimized for asynchronous IO operations, they are super cheap to create since they are just regular python objects, and you can generally create them in higher quantities since the event loop manages them efficiently for you.
Queues
Worker communicate between each other through Queues. The maximum number of elements each Queue can hold is controlled by the maxsize parameter in pypeln's various functions. By default this number is 0 which means there is no limit to the number of elements, however when maxsize is set it serves as a backpressure mechanism that prevents previous stages from pushing new elements to a Queue when it becomes full (reaches its maxsize), these stages will stop their computation until space becomes available thus potentially preveting OutOfMemeory errors on the slower stages.
The following table shows the relative communication cost between workers given the nature of their queues:
| Worker | Communication Cost |
|---|---|
Process |
high |
Thread |
none |
Task |
none |
General guidelines:
- Communication between
processesis costly since python objects have to be serialized, which has a considerable overhead when passing large objects such asnumpyarrays, binary objects, etc. To avoid this overhead try only passing metadata information such as filepaths between processes. - There is no overhead in communication between
threadsortasks, since everything happens in-memory there is no serialization overhead.
Resource Management
There are many occasions where you need to create some resource objects (e.g. http or database sessions) that (for efficiency) are expected to last the whole span of each worker's life. To support and effectily manage the lifecycle of such objects most of pypelns functions accept the on_start and on_done callbacks.
When a worker is created its on_start function get called. This function can return a dictionary containing these resource objects which can be consumed as arguments (by name) on the f and on_end functions. For exmaple:
import pypeln as pl
def on_start():
return dict(
http_session = get_http_session(),
db_session = get_db_session(),
)
def f(x, http_session, db_session):
# some logic
return y
def on_end(http_session, db_session):
http_session.close()
db_session.close()
stage = pl.process.map(f, stage, workers=3, on_start=on_start, on_end=on_end)
Dependency Injection
Special Arguments
worker_info:f,on_startandon_donecan define aworker_infoargument; an object with information about the worker will be passed.stage_status:on_endcan define astage_statusargument; an object with information about the stage will be passed.element_index:fcan define aelement_indexargument; a tuple representing the index of the element will be passed, this index represents the order of creation of the element on the original/source iterable and is the underlying mechanism by which theorderedoperation is implemented. Usually it will be a tuple of a single element, but operations likeflat_mapadd an additional index dimension in order to properly keep track of the order.
User Defined
Any element in the dictionary returned by on_start can be consumed as an argument by f and on_done.
Pipe Operator
Most functions can return a Partial instead of a Stage if the stage argument is not given. These Partials are callables that accept the missing stage parameter and call the computation. The following expressions are equivalent:
pl.process.map(f, stage, **kwargs) <=> pl.process.map(f, **kwargs)(stage)
Partial implements the pipe | operator as
x | partial <=> partial(x)
This allows pypeln to enable you to define your pipelines more fluently:
from pypeln import process as pr
data = (
range(10)
| pl.process.map(slow_add1, workers=3, maxsize=4)
| pl.process.filter(slow_gt3, workers=2)
| list
)